#load data
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.ticker import FuncFormatter
import datetime as dt
df=pd.read_csv('data.csv',encoding='latin1')
df.head()
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country |
|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 12/1/2010 8:26 | 2.55 | 17850.0 | United Kingdom |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 12/1/2010 8:26 | 2.75 | 17850.0 | United Kingdom |
| 3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom |
| 4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom |
df.dtypes
InvoiceNo object
StockCode object
Description object
Quantity int64
InvoiceDate object
UnitPrice float64
CustomerID float64
Country object
dtype: object
#transfer data type
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])
df['CustomerID']=df['CustomerID'].astype('object')
df.dtypes
InvoiceNo object
StockCode object
Description object
Quantity int64
InvoiceDate datetime64[ns]
UnitPrice float64
CustomerID object
Country object
dtype: object
#create time diff
R_today = dt.datetime(2021,8,7)
df['R_diff'] = (R_today - df['InvoiceDate']).dt.days
df.head(3)
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | R_diff |
|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 2010-12-01 08:26:00 | 2.55 | 17850 | United Kingdom | 3901 |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 2010-12-01 08:26:00 | 3.39 | 17850 | United Kingdom | 3901 |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 2010-12-01 08:26:00 | 2.75 | 17850 | United Kingdom | 3901 |
#create R,F,M
R = df.groupby(by=['CustomerID'])['R_diff'].agg([('R','min')])
M=df.groupby(by=['CustomerID'])['UnitPrice'].agg([('M','sum')])
#drop duplicates and calculate the recency
F_undone=df.drop_duplicates(subset='InvoiceNo')
F_undone.head(3)
F=F_undone.groupby(by=['CustomerID'])['CustomerID'].agg([('F','count')])
RFM = R.join(F).join(M)
RFM.head(3)
| R | F | M |
|---|
| CustomerID | | | |
|---|
| 12346.0 | 3853 | 2 | 2.08 |
| 12347.0 | 3530 | 7 | 481.21 |
| 12348.0 | 3603 | 4 | 178.71 |
RFM.describe()
| R | F | M |
|---|
| count | 4372.000000 | 4372.000000 | 4372.000000 |
| mean | 3619.581199 | 5.075480 | 322.008226 |
| std | 100.772139 | 9.338754 | 1284.783098 |
| min | 3528.000000 | 1.000000 | 0.000000 |
| 25% | 3544.000000 | 1.000000 | 52.865000 |
| 50% | 3578.000000 | 3.000000 | 130.095000 |
| 75% | 3671.000000 | 5.000000 | 302.332500 |
| max | 3901.000000 | 248.000000 | 41376.330000 |
#define R
RFM['R_revalue']=RFM['R']/365
RFM.head(5)
| R | F | M | R_revalue |
|---|
| CustomerID | | | | |
|---|
| 12346.0 | 3853 | 2 | 2.08 | 10.556164 |
| 12347.0 | 3530 | 7 | 481.21 | 9.671233 |
| 12348.0 | 3603 | 4 | 178.71 | 9.871233 |
| 12349.0 | 3546 | 1 | 605.10 | 9.715068 |
| 12350.0 | 3838 | 1 | 65.30 | 10.515068 |
#weight given: R(0.1)/F(0.5)/M(0.4)
RFM['value']=RFM['R_revalue']*0.1+RFM['F']*0.5+RFM['M']*0.4
RFM.head(3)
| R | F | M | R_revalue | value |
|---|
| CustomerID | | | | | |
|---|
| 12346.0 | 3853 | 2 | 2.08 | 10.556164 | 2.887616 |
| 12347.0 | 3530 | 7 | 481.21 | 9.671233 | 196.951123 |
| 12348.0 | 3603 | 4 | 178.71 | 9.871233 | 74.471123 |
RFM['value'].describe()
#most of the value under 124
#then we check the distribution of value which under 150
count 4372.000000
mean 132.332697
std 516.430006
min 1.470411
25% 22.965753
50% 54.611945
75% 124.896836
max 16568.499671
Name: value, dtype: float64
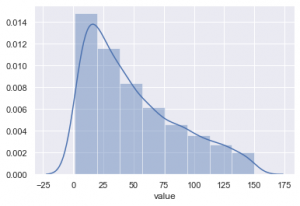
RFM_Common=RFM[RFM['value']<150]
sns.set()
sns.distplot(RFM_Common['value'],bins=8)
RFM_Common['value'].std()
38.006808099240864
RFM_Common['value'].mean()
49.523783395743465
#1.96 std contains 95% data, so the top limit should be 136
38+1.96 * 50
136.0
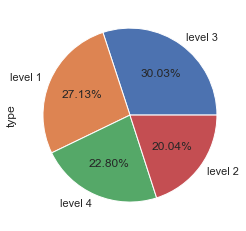
#set four levels of customers, 'level 4' are most valuable
bins=[0,25,50,136,16569]
RFM['type']=pd.cut(RFM['value'],bins,labels=['level 1','level 2','level 3','level 4'])
RFM['type'].value_counts().plot(kind='pie',autopct='%1.2f%%',subplots=True)
array([],
dtype=object)
#export customer list
df.to_csv('rfm.csv')
Recent Comments